


天河马新闻
炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
(来源:IT之家)
IT之家 11 月 9 日消息,研究人员用真实的手术录像对谷歌最新视频生成人工智能模型 Veo-3 进行了测试,结果发现该模型虽能生成高度逼真的视觉内容,却严重缺乏对医学操作流程的实质性理解。
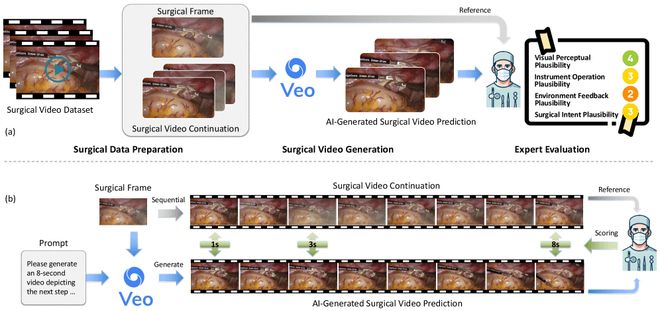
研究中,研究人员仅提供单张手术图像作为输入,要求 Veo-3 预测接下来 8 秒内的手术进展。为系统评估其表现,一支国际研究团队构建了名为 SurgVeo 的专用评测基准,涵盖 50 段真实腹腔与脑部手术视频。评估环节由四位经验丰富的外科医生独立完成,从视觉真实性、器械使用合理性、组织反馈表现及操作医学逻辑性四个维度对 AI 生成视频进行打分(满分 5 分)。
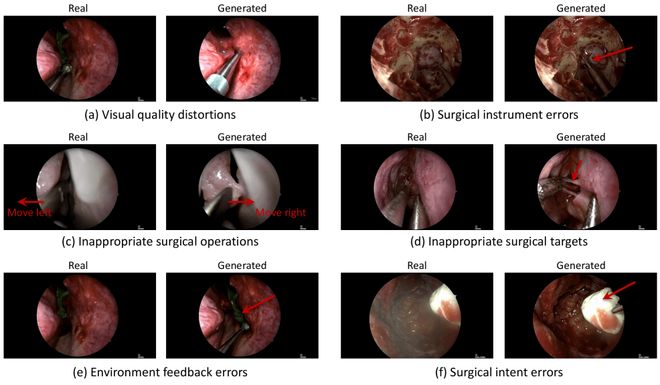
Veo-3 生成的视频初看极具欺骗性,部分外科医生甚至评价其画质“令人震惊地清晰”。然而深入分析后,其内容逻辑迅速崩塌:在腹腔手术测试中,模型在 1 秒时的视觉合理性尚达 3.72 分;但一旦涉及医学准确性,得分便大幅下滑 —— 器械操作仅 1.78 分、组织反应仅 1.64 分,而最核心的手术逻辑性评分最低,仅为 1.61 分。模型虽能生成高度拟真的影像,却无法再现真实手术室中应有的操作流程与因果关系。
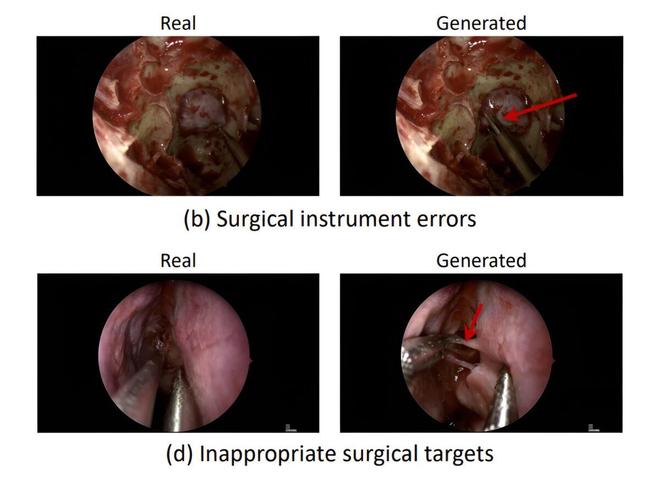
IT之家注意到,在对精细度要求极高的神经外科场景中,Veo-3 表现更为逊色。自第 1 秒起,其即难以把握神经外科所需的精准操作:器械使用得分降至 2.77 分(腹腔手术为 3.36 分),而 8 秒后的手术逻辑性评分更是跌至 1.13 分。
研究团队进一步归类错误类型发现:超 93% 的错误源于医学逻辑层面 —— 例如凭空“发明”不存在的手术器械、虚构违反生理规律的组织反应,或执行在临床上毫无意义的操作;而仅极小比例的错误(腹腔手术 6.2%、脑部手术 2.8%)与图像质量相关。
研究人员尝试为模型提供更多上下文线索(如手术类型、具体操作阶段等),但结果未呈现显著或稳定的改善。团队指出,问题核心并非信息缺失,而在于模型根本缺乏对医学知识的理解与推理能力。
SurgVeo 研究清晰表明:当前视频生成 AI 距离真正的医学理解仍有巨大鸿沟。尽管未来系统或有望用于医生培训、术前规划乃至术中引导,但现有模型远未达到安全、可靠的应用门槛 —— 它们可生成“以假乱真”的影像,却缺乏支撑正确临床决策的知识基础。
研究团队计划将 SurgVeo 基准数据集开源至 GitHub,以推动学界共同提升模型医学理解能力。
该研究亦警示:将此类 AI 生成视频用于医学培训存在重大隐患。与英伟达利用 AI 视频训练通用任务机器人不同,在医疗领域,此类“幻觉”可能带来严重后果 —— 若 Veo-3 类系统生成看似合理实则违反医学规范的操作视频,或将误导手术机器人或医学生习得错误技术。
结果还表明,当前将视频模型视为“世界模型”(world models)的设想仍过于超前。现有系统仅能模仿表观运动与形态变化,却无法可靠掌握解剖结构、生物力学及手术中的因果逻辑。其输出视频虽具表面说服力,实则无法捕捉手术背后真实的生理机制与操作逻辑。
天河马新闻
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






